· 7 min read
SigBreaker 1.0
See SigBreaker Stability Results
We’re excited to launch SigBreaker 1.0, a purpose-built binary diversification engine designed to disrupt static signature-based detection—without bloating binaries or hurting performance.
At the heart of SigBreaker is BLARE, our binary transformation framework that can identify and safely rewrite over 99% of functions in any binary. This level of coverage lets us apply extremely lightweight, high-throughput transformation passes that effectively break signatures, while preserving functional correctness and runtime efficiency.
How SigBreaker Works
SigBreaker 1.0 currently supports 64-bit x86 PE binaries and applies three core diversification techniques:
- Segment Selector Injection: Random segment prefixes (e.g. DS, SS, ES, etc) are inserted into memory operands. These segment overrides are chosen from a user-configurable whitelist, allowing safe use depending on the execution environment. On Windows, for example, FS and GS are reserved by the OS and must be handled carefully. Or an environment where segment descriptors may not be present.
- Instruction Reordering: Within basic blocks, SigBreaker reorders non-dependent instructions to break signatures while maintaining semantic equivalence.
- Basic Block Shuffling: Control flow is preserved while basic block order is randomized. This thwarts pattern-matching tools that rely on static layout assumptions.
Each of these passes is designed to be fast, safe, and composable. Because BLARE provides accurate control flow and data flow information, our transformations can be applied at scale without introducing subtle bugs or performance cliffs.
Segment Selector Injection
Injecting segment overrides into instructions with memory operands is a lightweight and effective way to break static signatures. If an instruction doesn’t already use a segment selector, adding one changes its encoding—often enough to evade pattern matching—without impacting runtime behavior.
SigBreaker applies this transformation selectively, using a user-defined probability and a customizable whitelist of allowed segment selectors. By default, we avoid inserting FS and GS, as these are special from the perspective of the x86_64 architecture. E.g. reserved by the Windows kernel and userland for Thread Environment Blocks (TEBs) and other critical structures. However, if your binary is intended for an alternative execution environment—such as UEFI, a custom OS, or a hypervisor—you can explicitly allow these segments or others to suit your needs.
This pass is fast and meaningfully breaks signatures at the instruction level, nullifying the effectiveness of signature-based scanners.
You can read more about x64 segmentation on Windows here.
Instruction Reordering
SigBreaker builds a dependency graph (DAG) for each basic block based on register usage, memory ordering, and calling convention constraints. This graph captures the true data dependencies between instructions. Edges in the DAG are introduced for:
- Register dependencies: read-after-write (RAW), write-after-read (WAR), and write-after-write (WAW)
- Memory ordering: load/store chains that must be preserved
- Call chains: respecting the order of function calls due to potential side effects
Once the DAG is constructed, SigBreaker applies a randomized variant of Kahn’s algorithm to produce a valid topological ordering. At each step, instructions are randomly selected from the current frontier (those with no unresolved dependencies), resulting in a semantically equivalent but uniquely ordered basic block.
This approach is extremely fast in practice, allowing SigBreaker to inject instruction-level entropy at scale without introducing bugs or performance overhead.
Here’s a sample DAG illustrating instruction dependencies:
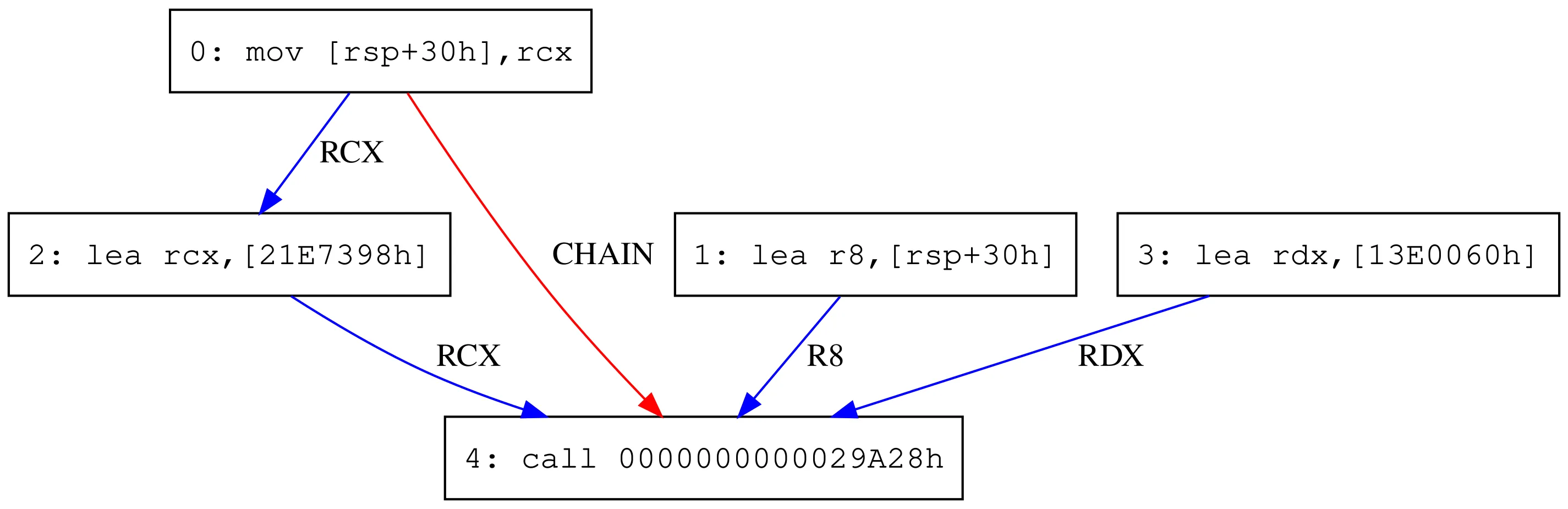
In this example, instructions 0, 1, and 3 can be reordered freely, but instruction 0 must precede both 2 and 4 due to dependency edges. This structure allows SigBreaker to inject randomness while honoring all necessary constraints.
Basic Block Re-ordering
SigBreaker reorders basic blocks by rewriting control flow to explicitly jump between blocks, allowing them to be laid out in any arbitrary order. This breaks assumptions made by signature-based tools that rely on static code layout or relative block positions.
Because control flow is preserved through inserted jmp instructions (when necessary), the program remains functionally identical while gaining a massive increase in structural randomness. Every build can feature a different block layout, making it significantly harder to rely on static offsets or linear scan patterns.
How SigBreaker Can Be Used
Static signature detection remains the backbone of both anti-cheat and malware analysis pipelines. From commercial anti-cheat engines like BattleEye and EAC to enterprise-grade endpoint security suites, the common denominator is reliance on pattern matching—identifying known byte sequences, control flow shapes, or instruction patterns to classify behavior.
In multiplayer games, cheaters reverse-engineer game binaries to locate key functions, patch logic, or inject custom code. These modifications are typically detected by anti-cheat systems scanning for static signatures and known code regions.
But with SigBreaker, game developers can diversify entire game binaries, rewriting upwards of 99% of functions while preserving semantics and performance. Each build of the game can be uniquely transformed—randomizing instruction order, shuffling basic blocks, and injecting safe segment prefixes—making it incredibly difficult for cheaters to find consistent signatures or offsets to hook into. All at minimal cost to performance.
This turns static pattern matching into a brittle and unreliable tactic. The same cheat tool won’t work across builds, and even automated reverse engineering tools become far less effective when the layout of the binary shifts from one build to the next. Due to SigBreaker’s inherent randomness developers can break cheat signatures without having to change or update any code.
In the malware analysis world, defenders use similar techniques to identify and classify known malware samples. But SigBreaker flips the model. Offensive tooling or research malware can be diversified on deployment, emitting semantically identical but structurally unique binaries per recipient.
This provides two major advantages:
- Evasion: Static AV signatures become ineffective when the byte structure and control flow of each binary is distinct.
- Attribution: If a binary is leaked or re-uploaded, the unique fingerprint introduced during transformation can help trace it back to the original recipient.
Whether you’re shipping hardened games, testing evasion strategies, or distributing sensitive research tools, SigBreaker gives you fine-grained control over the shape of your binaries—without sacrificing safety or speed. It’s not just about obfuscation. It’s about owning the fingerprint.
Build Uniqueness and Leak Attribution
Every binary processed by SigBreaker is structurally unique. Because of our randomized transformation passes—like instruction reordering, basic block shuffling, and segment selector injection—no two outputs are exactly the same. This per-build variability gives each binary a distinct fuzzy hash. This has powerful implications for leak attribution. If a protected binary is leaked or redistributed, the unique fingerprint introduced during SigBreaker’s transformation pipeline can be used to trace it back to the original recipient. Unlike watermarks or injected metadata, this fingerprint emerges naturally from structural entropy—making it incredibly difficult to strip or forge.
Because SigBreaker operates at high throughput and scales linearly with code size, generating unique builds for each distribution is fast and practical—even for large binaries. Whether you’re shipping to players, testers, partners, or internal teams, each binary can carry its own structural identity.
Limitations and Further Research
While SigBreaker 1.0 brings extensive diversification to instruction-level code, it currently does not target certain static features that can still aid signature-based detection. For example, constant values embedded in code—often used as anchors for matching—remain untouched. Likewise, SigBreaker does not yet modify the .data or .rdata sections, meaning global/static data remains a potential fingerprinting surface. We’re actively researching new ways to expand our transformation capabilities. One area of interest is the diversification of function prologues and associated unwind metadata. By safely rewriting these while preserving unwind correctness, we can make functions harder to identify and further reduce the effectiveness of static scanners. Our long-term vision is to evolve SigBreaker into a robust anti-tamper solution. That means transforming not just layout and structure, but also the semantic fingerprint of binaries—from metadata and constants to control flow and data sections—making static analysis brittle and modification far more difficult.
SigBreaker Stability Tests
To prove SigBreaker’s stability and correctness under real-world conditions, we’ve released a public GitHub repo showcasing how SigBreaker-processed binaries perform when subjected to LLVM’s extensive lit test suite.
LLVM’s test framework (lit) is used by compiler engineers to verify the functionality, correctness, and regressions of the entire toolchain—including Clang, LLD, and more. These tests aren’t just trivial smoke tests—they cover everything from parsing edge cases to backend codegen, and even subtle linker behavior.
We ran 100% of the clang and lld test suites using:
- Original LLVM binaries, and
- SigBreaker-transformed binaries, where almost every function was fully scrambled.
The results of almost 47,000 tests show that both binaries perform the same functionality. You can reproduce these impressive results yourself by following the instructions on this github repo: https://github.com/backengineering/sigbreaker-llvm-lit
If you are interested in using SigBreaker, feel free to contact us here, or send an email to [email protected].